Lab2.5-手写 SIMD 向量化
Lab2.5-手写 SIMD 向量化
实验简介
1 | 需要完成的任务非常简单,将下列循环使用手写 SIMD 向量化的方式进行优化。(因为是作为手写 SIMD 向量化的例子 |
基准代码
1 | for (int n = 0; n < 20; ++n) { |
中间代码
1 | for (int n = 0; n < 20; ++n) { |
思路分析
先改写成中间代码,四个为一组进行计算,为改写成向量化作过渡。四个为一组是因为 SSE 中可以把 128 位当作一个向量,而 float 类型有 32 位。(理论上来说采用 AVX 中 8 个为一组可以更加有效提升效率)
然后通过引用
<emmintrin.h>头文件,来使用 SSE 指令集。使用__m128 _mm_load_ps (float const* mem_addr)函数来载入数据,void _mm_store_ps (float* mem_addr, __m128 a)函数来存储,__m128 _mm_add_ps (__m128 a, __m128 b)和__m128 _mm_mul_ps (__m128 a, __m128 b)函数来完成计算即可。
完成向量化
1 | for (int n = 0; n < 20; ++n) { |
正确性验证与加速比计算(ps:增加了一个计时器)
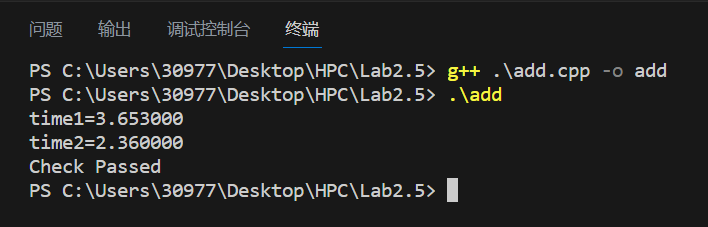
\[ S_p = \frac{T_1}{T_p} = \frac{3.653000}{2.360000} \approx 1.55 \]
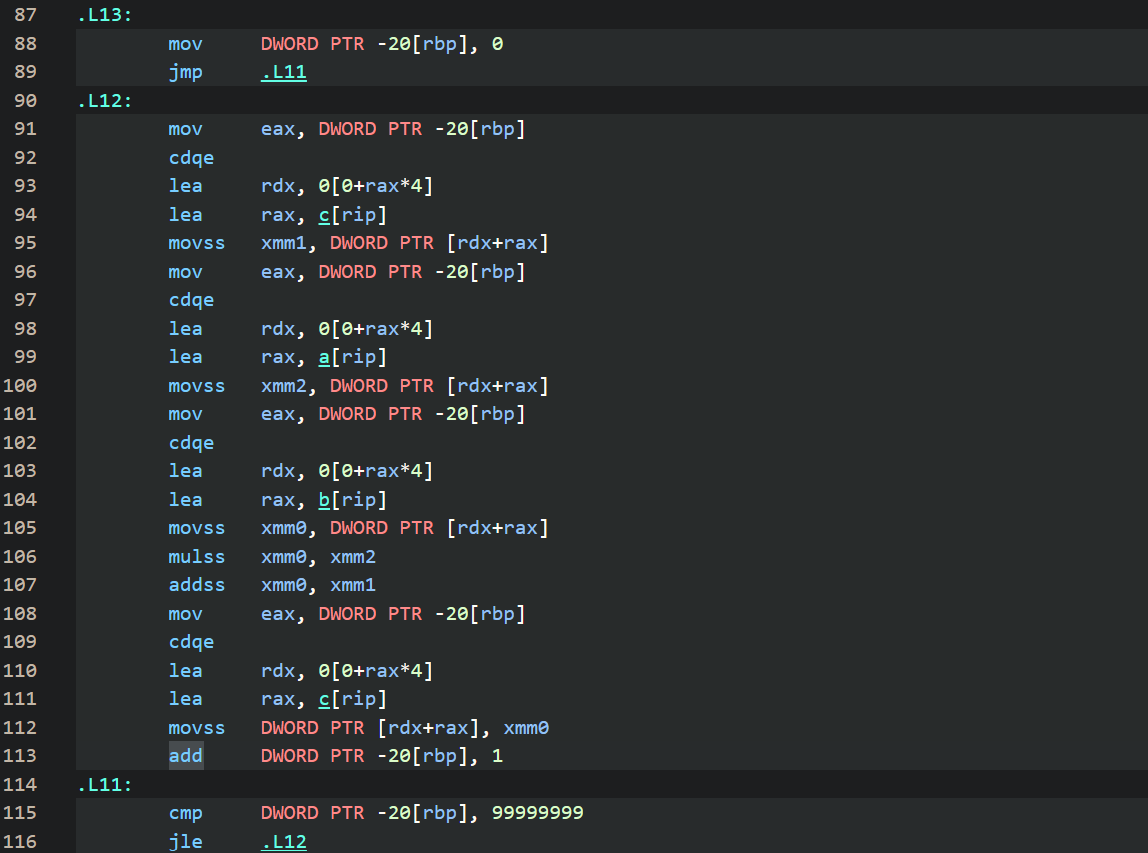
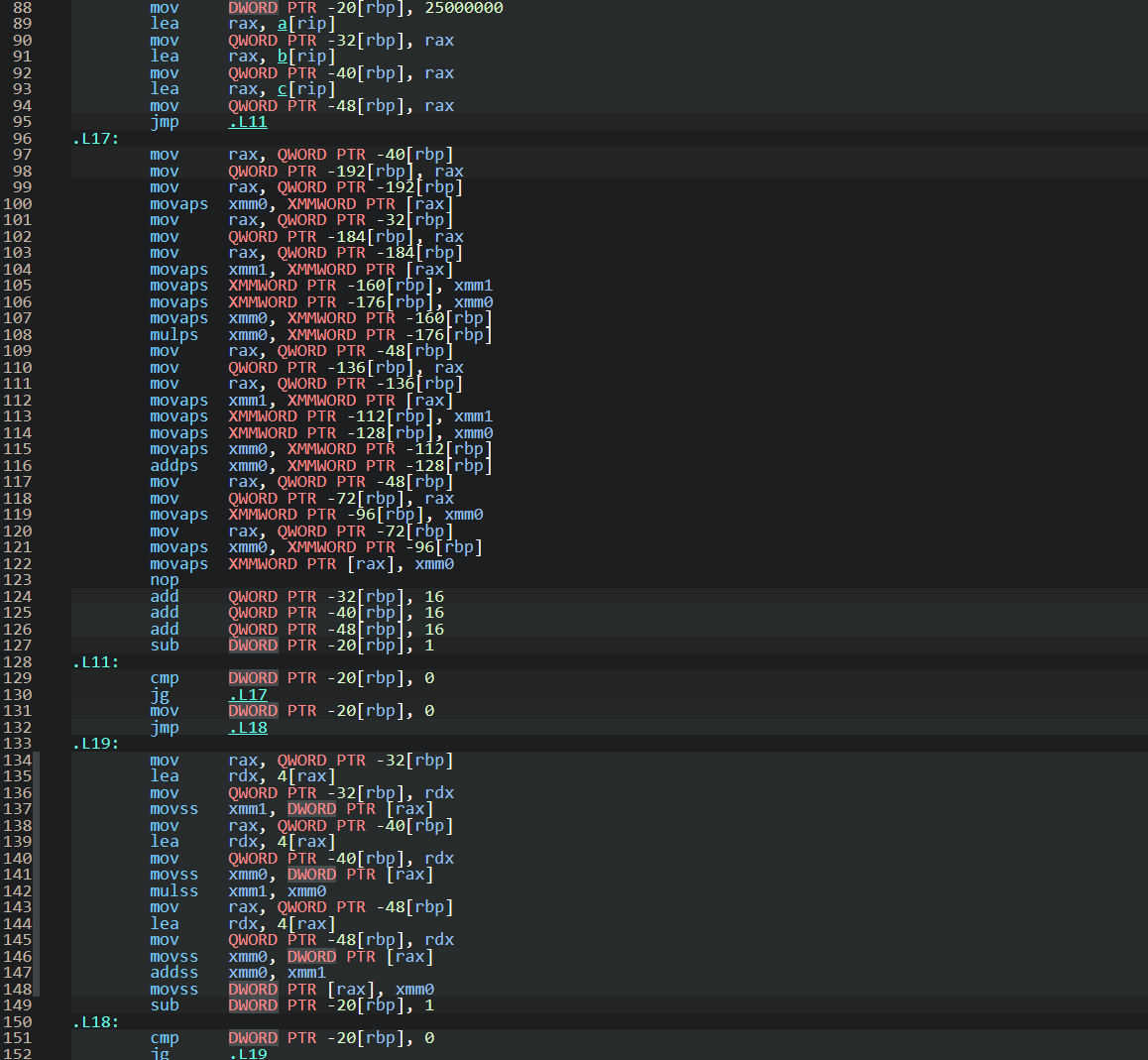
汇编代码比较
基准程序
向量化程序
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 理想乡 & zsh 的博客!