Lab4-PCG Solver
Lab4-PCG Solver
实验简介
1 | PCG 是一种利用多次迭代对方程组进行求解的方法。相比于使用直接法求解方程组,其对于存储空间的要求不高且扩展 |
基准代码
访存优化
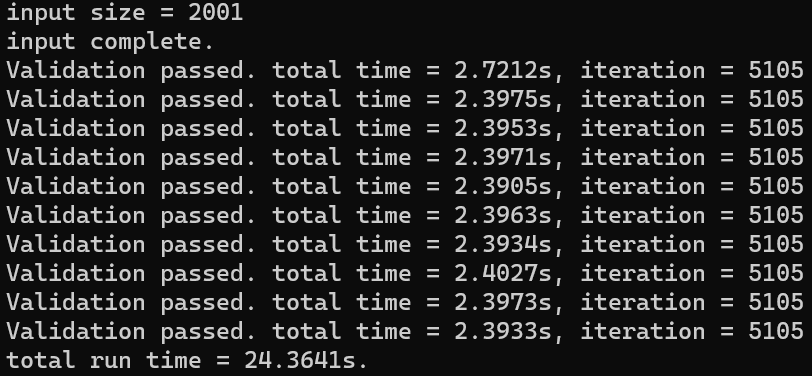
程序中对于内存的访问几乎全为线性,因此没有进行数组封装。矩阵分块和循环展开的操作也是配合 OpenMP 和 MPI 一起使用进行优化的。
SIMD
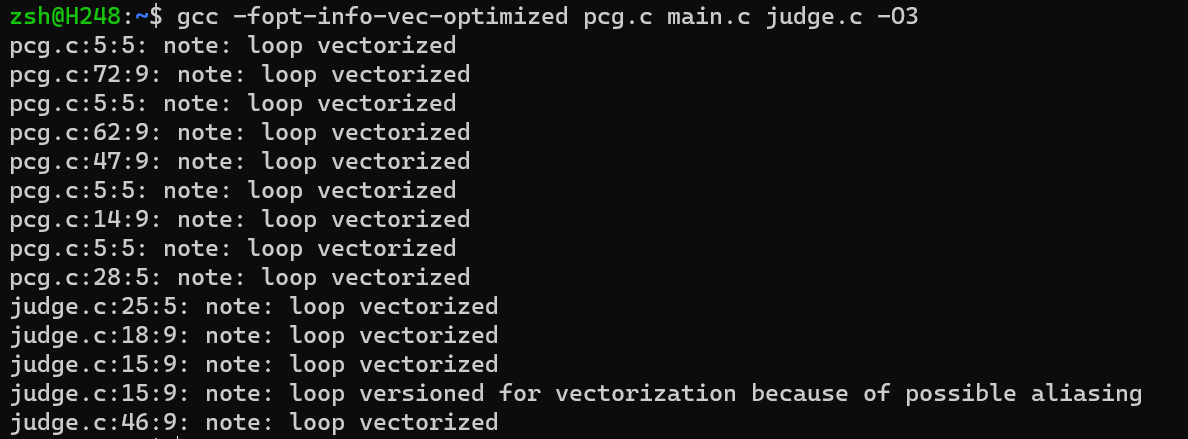
通过
gcc -fopt-info-vec-optimized pcg.c main.c judge.c -O3
命令来观察 -O3
编译选项下的自动向量化情况,可以知道的是大部分循环已经被自动向量化。
OpenMP
PCG
算法中包括点积、矩阵乘法和加法这些并行性质良好的运算,因此对于简单的一层
for 循环,我们可以直接使用 OpenMP 进行循环展开。
1 | double dot(double a[], double b[], int size){ |
1 |
|
仅仅这样循环展开并没有提升效率,用
#pragma omp parallel for simd 的话效率有略微提升。
MPI
并行化 PCG 算法,主要并行的部分是矩阵乘法部分,也就是基准代码中的
dot 和 MatrixMulVec
函数,因此可以让主进程去跑迭代循环,其中的计算分发到从进程上执行。
迭代中复杂度最高的运算就是 MatrixMulVec 函数,这是一个
\(\rm{size} \times \rm{size}\) 的矩阵和
\(\rm{size} \times 1\)
的向量作乘法运算,因此我们可以把 \(\rm{size}
\times \rm{size}\)
的矩阵进行分块,每块交给一个进程去做计算,最后用 MPI 通信结果。(用
OpenMPI 竟然比 IntelMPI 快不少 ×)
1 | void MPI_MatrixMulVec(int begin_row, int end_row, int size, double A[][size], double x[]) { |
1 |
|
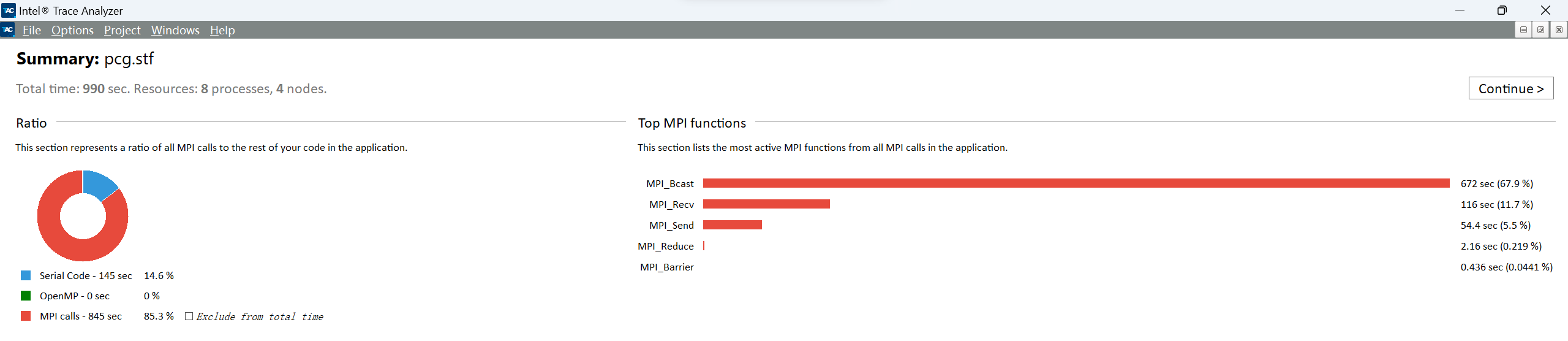
耗时最多的三个MPI函数分别是 MPI_Bcast 、
MPI_Recv 、
MPI_Send,程序在MPI上消耗的总时间为 845 sec。
完成 PCG 加速
修改代码
显然算完矩阵乘法后从进程闲着没事干,所以可以并行化
do-while循环里的其他运算。在尝试一个个单独并行化后发现,对于向量加减 mpi 的作用为负优化,只有在dot运算上有略微加速。dot函数的并行化很简单,只需要分段计算再用MPI_Reduce归约起来就可以了。这里只优化了上面的点积,是因为下面的点积如果要进行优化需要MPI_Bcast两组数据。1
2
3
4// 主进程
MPI_Bcast(A_dot_p, size, MPI_DOUBLE, master, MPI_COMM_WORLD);
MPI_Reduce(&other_dot, &master_dot, 1, MPI_DOUBLE, MPI_SUM, master, MPI_COMM_WORLD);
alpha = r_dot_z / master_dot;1
2
3
4// 从进程
MPI_Bcast(A_dot_p, size, MPI_DOUBLE, master, MPI_COMM_WORLD);
other_dot = MPI_dot(begin_row, end_row, p, A_dot_p);
MPI_Reduce(&other_dot, &master_dot, 1, MPI_DOUBLE, MPI_SUM, master, MPI_COMM_WORLD);编译参数
Makefile
1 | CC = mpicc |
- 运行参数
job.sh
1 |
|
尝试绑核
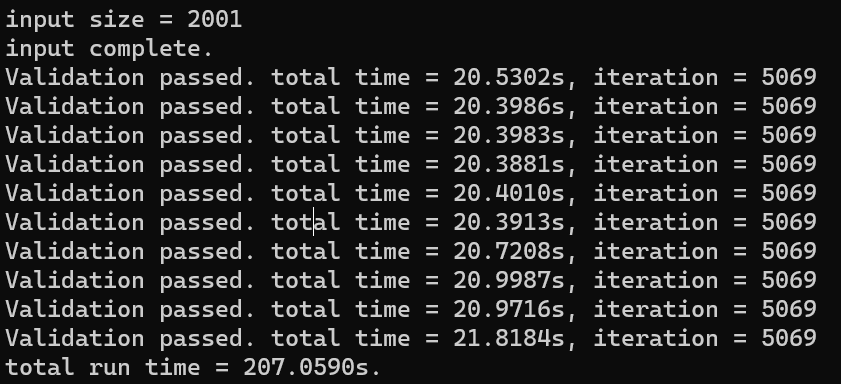
job.sh里的--bind-to core可以将进程与核心进行一个绑定,绑核对于 OpenMP 程序的性能有很大的影响,在绑核前直接使用 OpenMP 进行循环展开的话会严重降低 OpenMPI 程序的效率(不知为何对 IntelMPI 程序影响比较小🥶),在绑核后进行 reduction 操作就不会严重降低性能了(但还是会降低。因为绑核的失败,所以最后没有采用 OpenMP。加速效果
经检测
input_2.bin和input_3.bin的数据也能通过检测。\(6001 \times 6001\) 约 3 分钟, \(8001 \times 8001\) 约 10 分钟。